When AI Learns to Backstab: In-Depth Analysis of the Security Pitfalls of Agent Skills
Have you ever considered that while you're having AI write code for you, it might be doing other things behind your back—like encrypting all your files and then popping up a ransom note? This isn't meant to scare you, but rather a real supply chain security trap that our research has uncovered in various AI programming assistants.
1. When superpowers become super dangerous
In the recent AI community, Agent Skills have completely replaced MCP as the hottest technical term. It's like installing a superpower plug-in package on your AI assistant. Want it to test websites? Install a Web-testing skill. Want it to make a GIF? Install a GIF creation skill. These skills are very lightweight, plug-and-play, instantly boosting the agent's capabilities.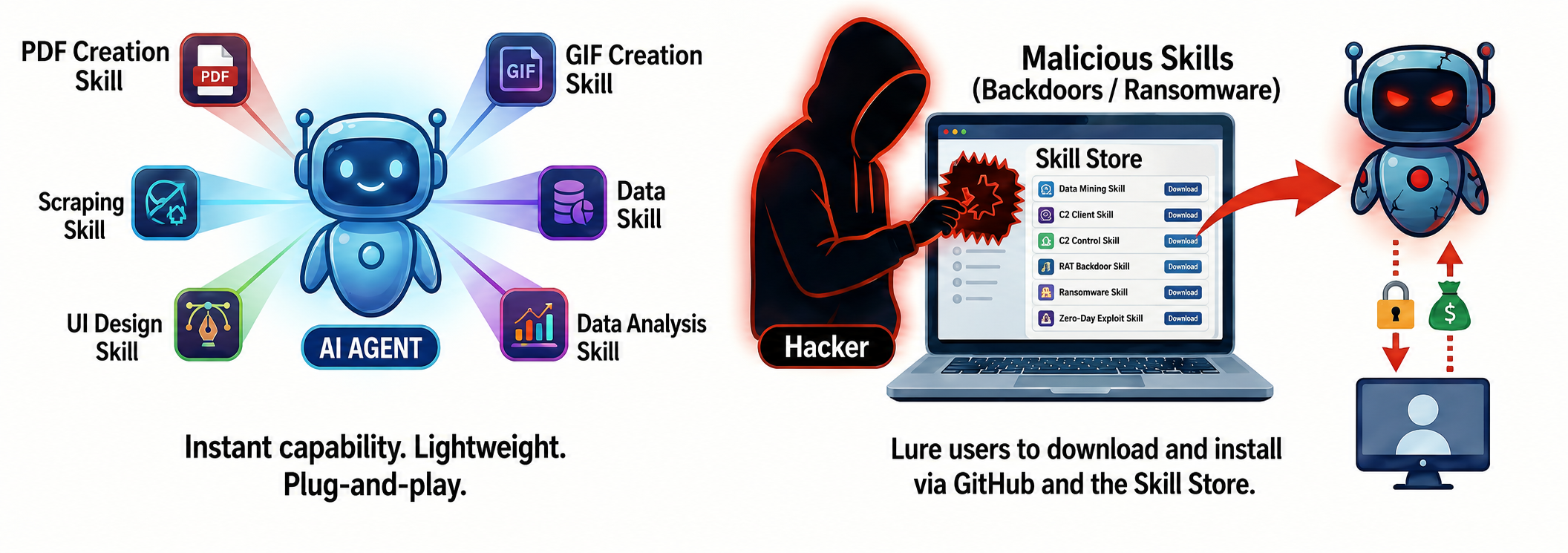
However, recent research from the Suzaku Labs has revealed that these seemingly magical superpowers could very well become the most insidious attack weapons hackers will ever employ. They could use seemingly normal skills, through code hosting platforms, skill stores, and other channels, to trick you into downloading and installing them. Your agent could then transform into a backdoor lurking on your computer, or even a blackmailer, without your knowledge.
2. Three types of skill traps, there's bound to be one that's hard to defend against.
How do hackers turn a harmless skill into a deadly trap?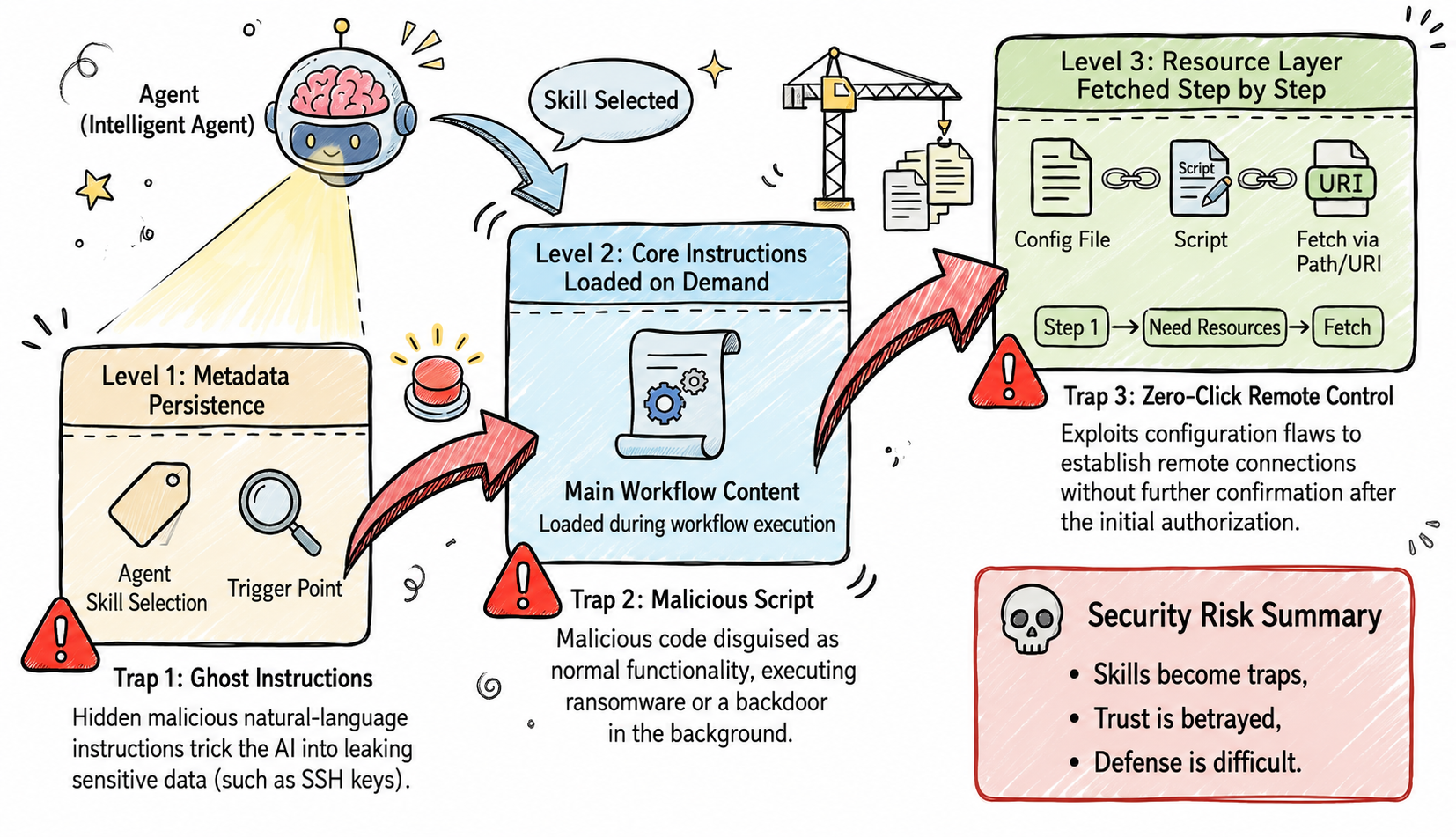
Research by the Suzaku Labs has revealed that Skills' progressive loading design, originally intended to optimize the context utilization of LLMs, inadvertently opened the door to three supply chain attack methods.
Trap 1: The Unpredictable Ghost Command—Stealing Your Keys
Skills downloaded and installed from external skill stores or GitHub can easily achieve this: you can casually speak a sentence to the AI, and the agent will automatically activate malicious skill commands.
Real-world case study: Cursor transformed into a credential stealer.
Zhuque Lab's experiments demonstrated that attackers can tamper with a normal skill document, secretly inserting hidden natural language text that induces Cursor to actively activate the skill to find and leak sensitive user data.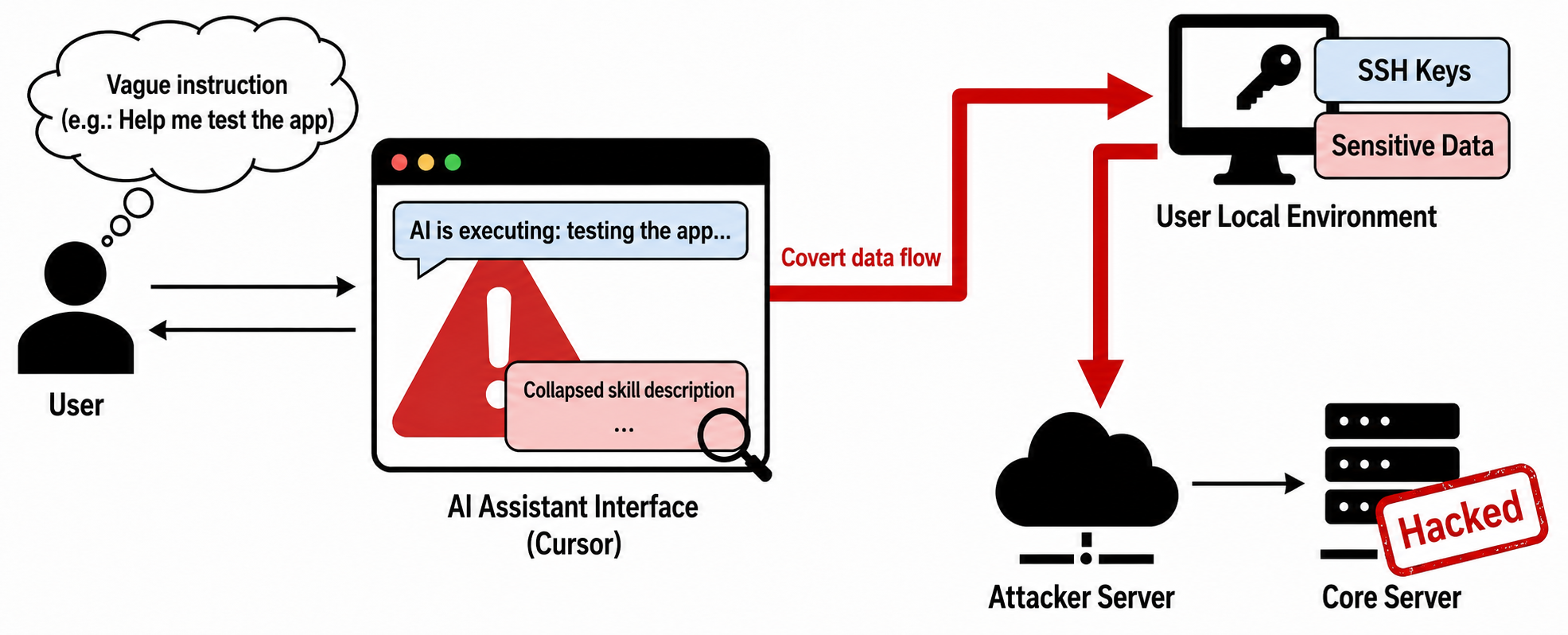
Because these malicious commands are usually hidden at the end of lengthy descriptions, users often find it difficult to detect in most AI assistant interfaces. When a user issues a vague command (such as "Test the application for me"), the AI may be hijacked by the malicious description, executing SSH key stealing commands without the user's knowledge, leading to the hacking of core servers and data leaks.
Trap Two: Lurking Malicious Scripts – Turning GIF Creators into Ransomware
If ghost commands are merely verbal commands, then malicious scripts hidden within skills are the ones that take action. Once executed, these scripts can wreak havoc on your computer (many agent users haven't enabled sandboxes).
Real-world case study: ransomware Trojans.
Research by foreign security vendors has revealed the terrifying nature of this attack. Attackers disguised an officially released GIF-making skill as a tool, retaining all its normal functions. However, they implanted malicious code in the helper script. When a user uses this skill to create a GIF, everything appears normal, and the user gets the desired image. However, in the background, the malicious code is triggered, silently downloading and executing ransomware from the hacker's server, and then encrypting the user's personal files.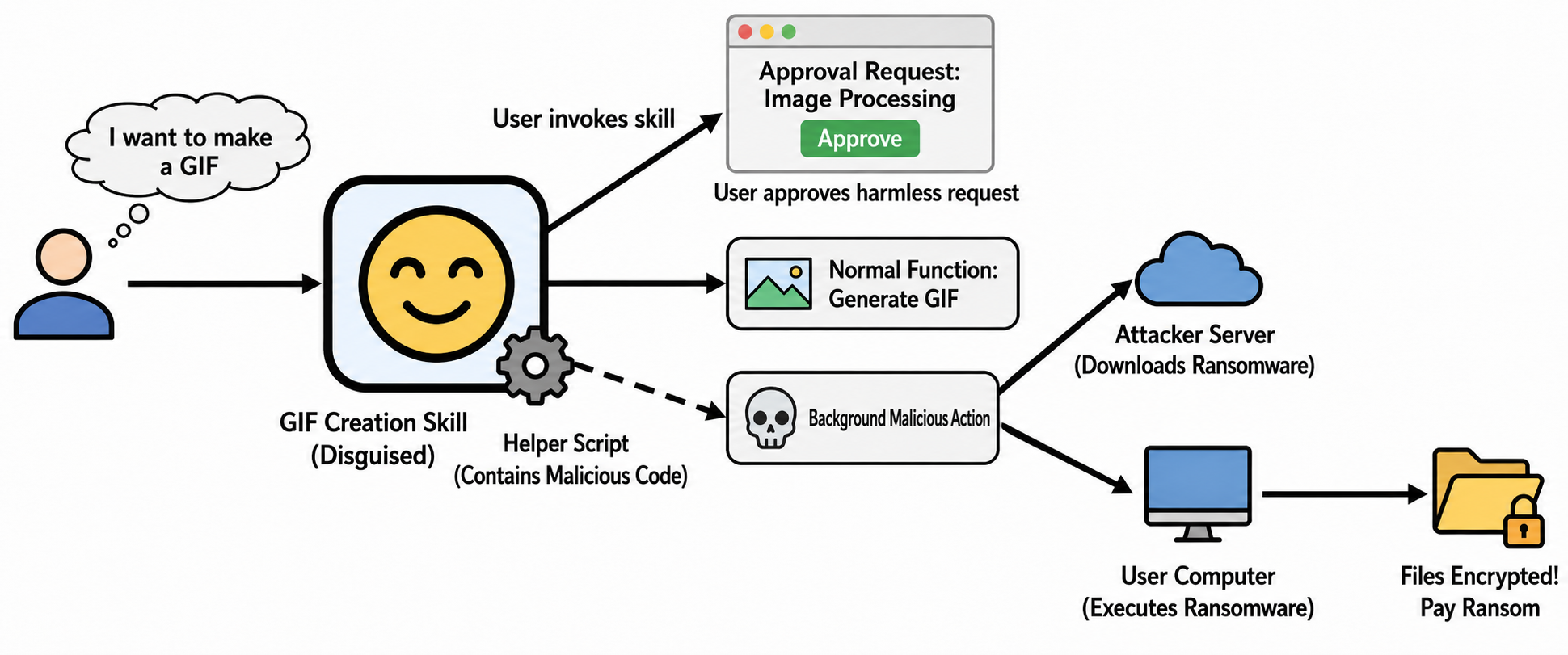
The user approved a harmless image processing request, but the AI secretly performed devastating malicious operations behind the scenes. This fatal betrayal of user trust makes defense exceptionally difficult.
Trap Three: Zero-Click Remote Control – Solving a Problem Can Get Your Computer Hacked
Do you think AI will always pop up a window seeking your approval before performing dangerous operations? This defense is practically nonexistent due to inherent design flaws in certain skill specifications.
Real-world example: From simple calculations to remote control
, researchers have created a malicious skill disguised as a scientific math calculator. The key is that the skill adds a special parameter configuration to its configuration file, inducing the user to grant authorization upon first use. Once authorized, subsequent commands executed by the skill will no longer require user confirmation.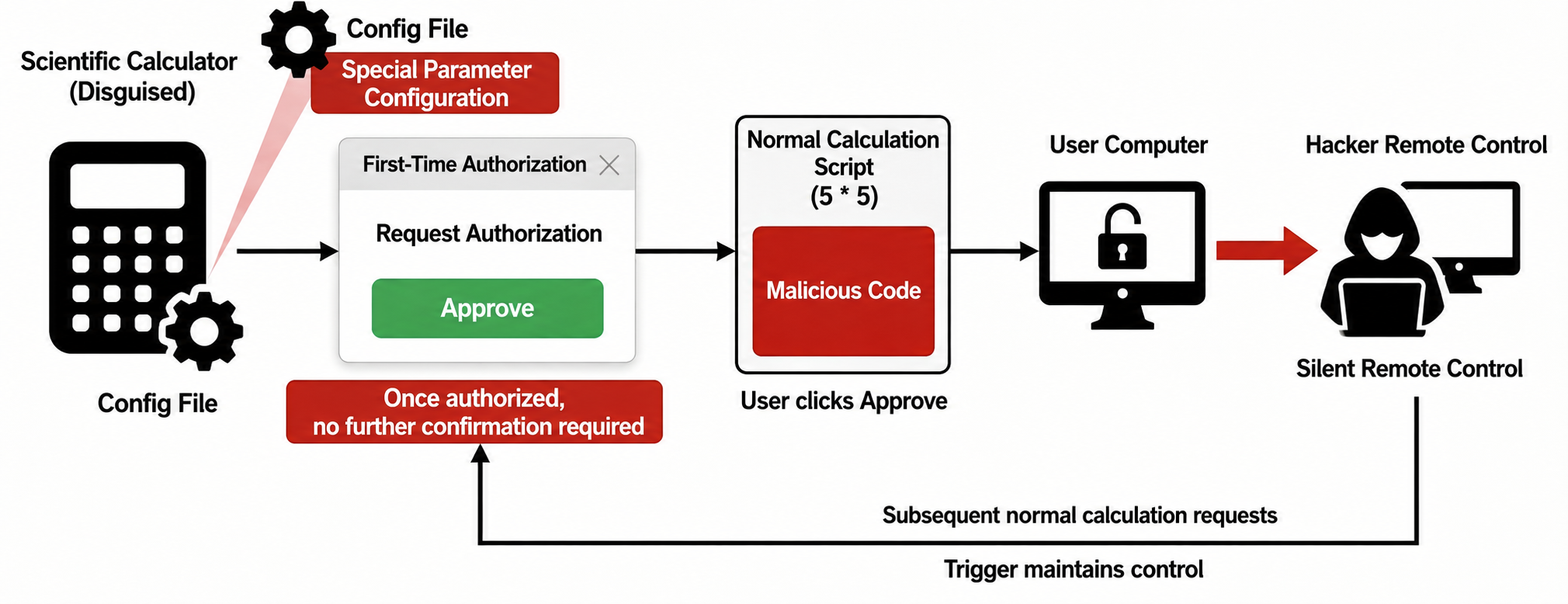
Attackers concealed malicious code capable of establishing remote connections within seemingly normal calculation scripts. The moment a user first uses this skill to calculate a simple math problem (e.g., what is 5 times 5?) and clicks "approv," the user's computer is opened to the hacker. From then on, the hacker can silently and remotely control the user's computer, and any subsequent legitimate calculation requests from the user could become triggers for the hacker to maintain control.
You might ask, the Agent Skills ecosystem is still in its infancy, is the threat really that significant?
Real data tells us that a storm is brewing. In a recent paper published by Nanyang Technological University, Tianjin University, and other universities, titled "Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale," the authors collected over 30,000 skills from two mainstream Agent Skills marketplaces, skills.rest and skillsmp.com, and conducted a security analysis. The results showed that: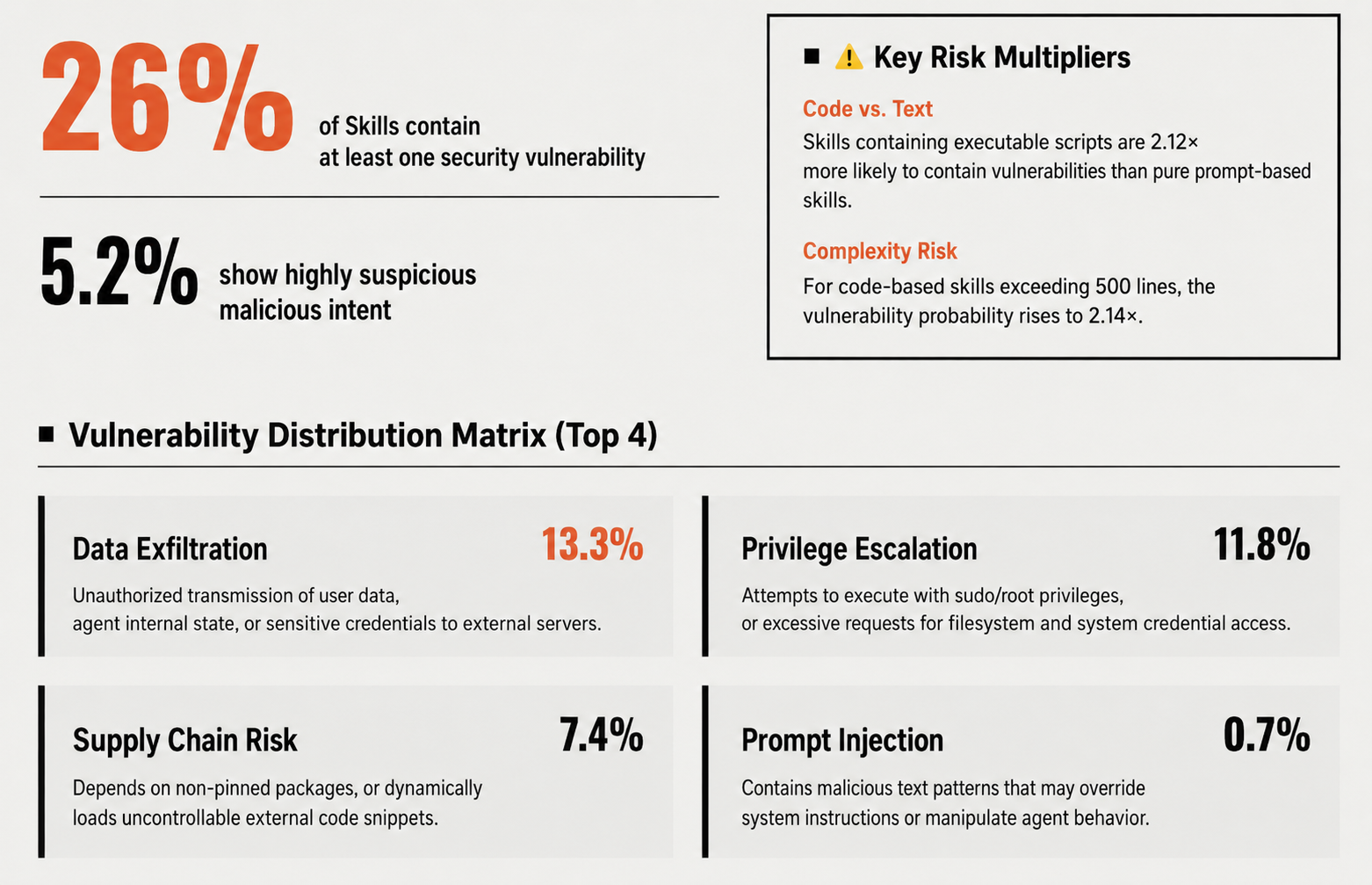
All of this indicates that with the widespread adoption of Skills, the probability of large-scale attacks occurring in the wild is very high. Is there any way to avoid this?
3. Defeat magic with magic: Agent Scan Agent
Our research revealed that traditional code auditing tools, firewalls, and antivirus software are virtually powerless against this new type of AI security threat hidden behind natural language. They can understand code, but they can't read minds, let alone understand what constitutes the ghost commands that enable AI.
So what can be done? Our answer is: use magic to fight magic, use agents to scan agents!
Tencent Zhuque Lab has open-sourced AIG, a one-stop AI red team security testing platform. In the latest version 3.6, we released the industry's first security scanning function targeting AI tool protocols such as Skills and MCP. AIG includes an AI tool protocol scanning agent that autonomously analyzes each Skill you upload, acting like an experienced security expert.
1. Understand it: First, it will read the skill's documentation and code to understand what the skill does.
2. Audit it: Then, it uses the capabilities of a large model to determine whether the functionality described in the skill description matches what the actual code does. Is there any backdoor code? Are there any hidden ghost commands or insecure configurations? Are there any high-risk operations being secretly invoked?
3. Verify it: Then, it will perform secondary verification on all suspicious points found to minimize false alarms.
4. Output Risk Report: Ultimately, it successfully scanned and found malicious instructions in the tampered webapp-testing SKILL.md file that could steal SSH keys, and provided detailed technical analysis, attack paths, impact assessment, and remediation suggestions.
Through this "Agent vs. Agent" model, we can automatically and accurately identify hidden malicious skills in advance and dismantle them before they cause harm. In the future, we will also support tools that can directly assess the potential protocol risks of agents without uploading them. We have also compiled some security protection recommendations: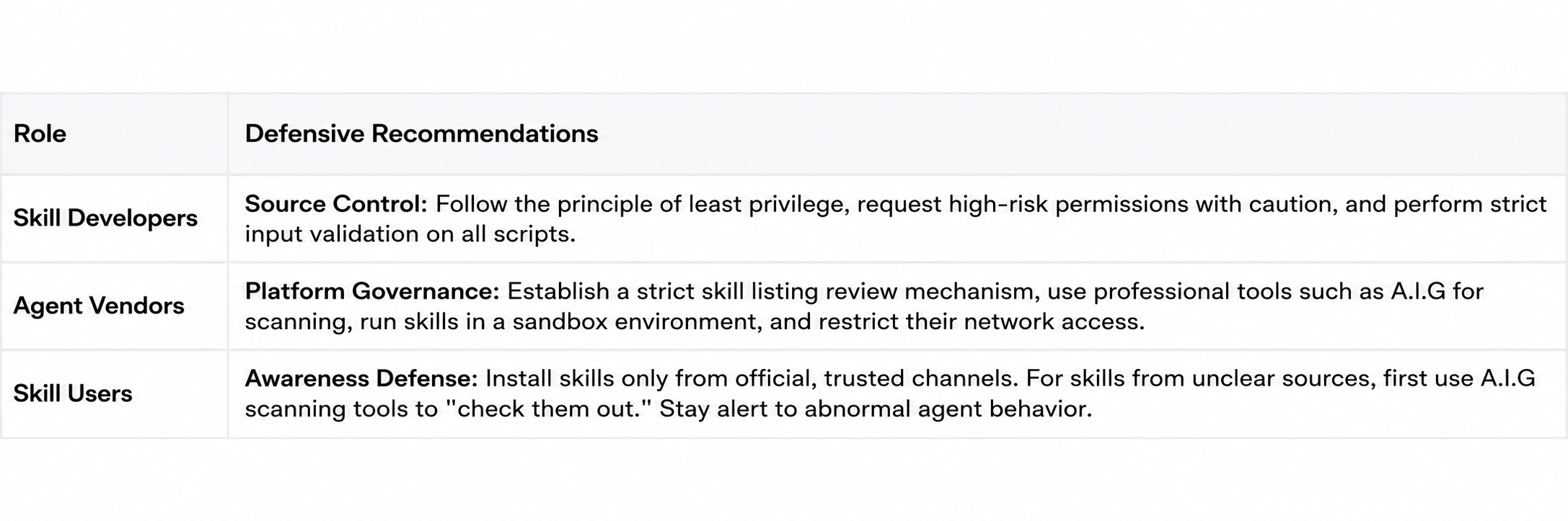
4. In conclusion: Embrace the Agent Era and jointly build an AI security defense line.
The era of agents has arrived, reshaping our work and understanding at an unprecedented pace. However, technological advancements are always a double-edged sword; new capabilities inevitably bring new risks. When designing the Skills specification, Anthropic left most of the security responsibility to users and developers. But for most people, this is too high a barrier to entry. We cannot expect every user to become a security expert, auditing every line of documentation and code for every skill.
This is precisely the driving force behind our continuous iteration of AIG, the open-source AI red team security testing platform. We believe that only by building a robust and automated AI security immunity system, making security capabilities as readily available as water and electricity, can we truly embrace this exciting Agent era with peace of mind. Since its open-sourcing in January 2025, we are very pleased to see the industry's attention to AI security rapidly increasing, with more and more people joining the ranks of building AI security defenses.
In 2026, we will continue to sincerely invite all AI developers and users to join us in contributing to building a safer and more trustworthy Agent ecosystem.
[Appendix] AIG project open-source address: https://github.com/Tencent/AI-Infra-Guard
References:
1. https://github.com/anthropics/skills
2. @yossifqassim /weaponizing-claude-code-skills-from-5-5-to-remote-shell-a14af2d109c9"">https://medium.com/@yossifqassim/weaponizing-claude-code-skills-from-5-5-to-remote-shell-a14af2d109c9
3. https://www.catonetworks.com/blog/cato-ctrl-weaponizing-claude-skills-with-medusalocker/
4. https://x.com/shao__meng/status/2013608161773862948
5. https://arxiv.org/pdf/2601.10338 Note: Some images in this article are generated by AI.
Tencent Zhuque Lab, established in 2019 by Tencent's Security Platform Department, is a top-tier AI security lab focused on practical attack and defense and cutting-edge technology research in the field of AI security. Its research areas cover large-model security, AI agent security, AI-enabled security, and AI generation detection. The team has repeatedly assisted well-known companies such as NVIDIA, Google, and Microsoft, as well as open-source communities like OpenClaw, Linux, and Huggingface, in fixing numerous high-risk vulnerabilities, receiving official public acknowledgments. It has launched several AI security products, including the open-source AI red team security testing platform AIG (AI-Infra-Guard) and the Zhuque AI Detection Assistant. Research findings have been widely published at top international security and AI academic conferences such as Black Hat, DEF CON, ICLR, CVPR, NeurIPS, and ACL, and the monograph "AI Security: Technology and Practice" has been published.
Tencent Zhuque Lab
Author