Who is the strongest gatekeeper for Agents? SkillTrustBench, the first benchmark for Agent skill security assessment, is officially released.
Introduction
As agent skills rapidly integrate into the AI application ecosystem, they are gradually becoming a new security perimeter and entry point for supply chain attacks. Building a secure and trustworthy skill runtime environment has become an industry consensus to prevent data breaches and agent hijacking caused by malicious skills. Although mainstream skill marketplaces such as ClawHub have implemented detection mechanisms, and numerous scanning tools have emerged from the open-source community, users often face a dilemma in practical implementation.
On the one hand, some scanning solutions prioritize high recall but frequently generate false positives, easily leading to security alert fatigue. On the other hand, while some solutions are accurate in their detection, they are prone to missing detections when facing covert adversarial techniques. Furthermore, LLM-based scanners exhibit significant differences in judgment preferences when switching underlying models. In the absence of systematic evaluation standards, the industry urgently needs objective benchmarks to measure both the detection effectiveness of security solutions and the security reliability of the skill itself.
To address these pain points, Tencent Zhuque Lab, in collaboration with Professor Wu Baoyuan's research group at the Chinese University of Hong Kong, Shenzhen, officially released SkillTrustBench —the first dual evaluation benchmark designed for real-world scenarios, balancing the security and trustworthiness of Agent Skills with the detection efficiency of external scanning solutions. This benchmark extracts 5,520 evaluation cases from 62,652 Skills in the mainstream skill market, covering nine major categories of common security threats, providing an objective reference for assessing and improving the security of Agent Skills.
From the initial evaluation data, we summarized several key points:
Performance of large model bases: In this evaluation, Claude Opus 4.6 and GLM 5.1 demonstrated extremely strong semantic reasoning and security constraint understanding capabilities in security scanning scenarios, placing them in the top tier; DeepSeek V4 Flash and Hy3 preview achieved an excellent balance between performance and cost, with significant cost-effectiveness advantages.
Performance of open-source tools: Lightweight open-source auditing solutions, such as OpenClaw + Skill Vetter, have the basic ability to detect most malicious skill risks, but there is still considerable room for improvement in controlling false alarms under complex noise interference.
The security and trustworthiness of the skills themselves: The evaluation found that many non-malicious skills also have potential for untrustworthiness. Insecure coding flaws such as hard-coded credentials, abuse of sensitive permissions, and vulnerability to command injection are widespread. Although these behaviors are not intentionally harmful, their inherent security vulnerabilities make them highly susceptible to becoming secondary attack entry points for supply chain hijacking.
Project website ( click to read the original article ): https://matrix.tencent.com/skilltrustbench
HuggingFace Dataset: https://huggingface.co/datasets/cuhk-zhuque/SkillTrustBench
HuggingFace Leaderboard: https://huggingface.co/spaces/cuhk-zhuque/SkillTrustBench-Leaderboard
01 The attack surface of Agent Skills is expanding
The danger of Agent Skills stems from their complex nature. A Skill transcends natural language, code, dependencies, permissions, and runtime context. It can issue direct instructions to the Agent in documents, transmit data via network requests, or launch covert attacks by executing local scripts, installing external dependencies, or tampering with session memory.
In the ClawHavoc incident at the end of January 2026, 1,184 malicious skills were uploaded to the ClawHub marketplace, resulting in 247,000 installations. A subsequent report by Snyk, ToxicSkills, showed that 36.82% of the skills on the marketplace had at least one security issue; the SkillProbe audit found that high download volume does not equate to greater security, and over 90% of the most popular skills on ClawHub still posed a risk.

In April 2026, Tencent Zhuque Lab used AIG (AI-Infra-Guard: https://github.com/Tencent/AI-Infra-Guard , Tencent Zhuque Lab's open-source one-stop AI red team security testing platform ) to conduct a full scan of skills on ClawHub. The study showed that ClawHub grew from less than 2,000 skills to over 50,000 in 90 days; even after the platform subsequently launched security detection mechanisms, risk signals in the skill ecosystem remained dense.
First, malicious Skills have shown signs of large-scale, matrix-like production. Behind the 50,000 Skills are 15,427 developers, but the top 20 publishers collectively released 5,422 Skills, accounting for 12.9% of the total; extreme accounts released 955 Skills in three months, averaging 10.6 per day. Multiple groups of accounts with similar names and alternating release times indicate that the Skill ecosystem has reached a point where mass production, mass deployment, and mass masquerading are possible.
Second, permission combinations naturally align with data leakage paths. Of the nearly 50,000 Skills, 27,818 declared network request permissions, accounting for 74.6%. Connecting to the internet itself isn't the problem, but when reading files + connecting to the internet becomes a common combination for many Skills, malicious transmission can be hidden within normal functional traffic.
Third, external access channels are highly fragmented. A full scan revealed 246,378 URLs pointing to 29,196 different domains. These could be legitimate APIs, documentation, or dependency sources, or they could serve as channels for remote control, data backhaul, on-chain interactions, or two-stage payload downloads.
02 Why are existing scanning and evaluation methods insufficient?
Following the ClawHavoc incident earlier this year, skill marketplaces and security vendors have begun building scanning mechanisms. For example, ClawHub has added built-in LLM security assessments and VirusTotal external link detection. These mechanisms can effectively block most brute-force attacks that directly embed malicious instructions in the SKILL.md ( https://SKILL.md ) document or directly download and run Trojan programs.
But the attackers quickly moved to the next stage: instead of writing the malicious logic explicitly, they used input truncation, file type blind spots, inconsistencies between source code and distribution products, corporate compliance rhetoric, and social engineering interpretations to bypass the scans.
In June 2026, Trail of Bits conducted bypass tests against ClawHub, Cisco skill scanner, and multiple scanners integrated into skills.sh. Their constructed samples included:
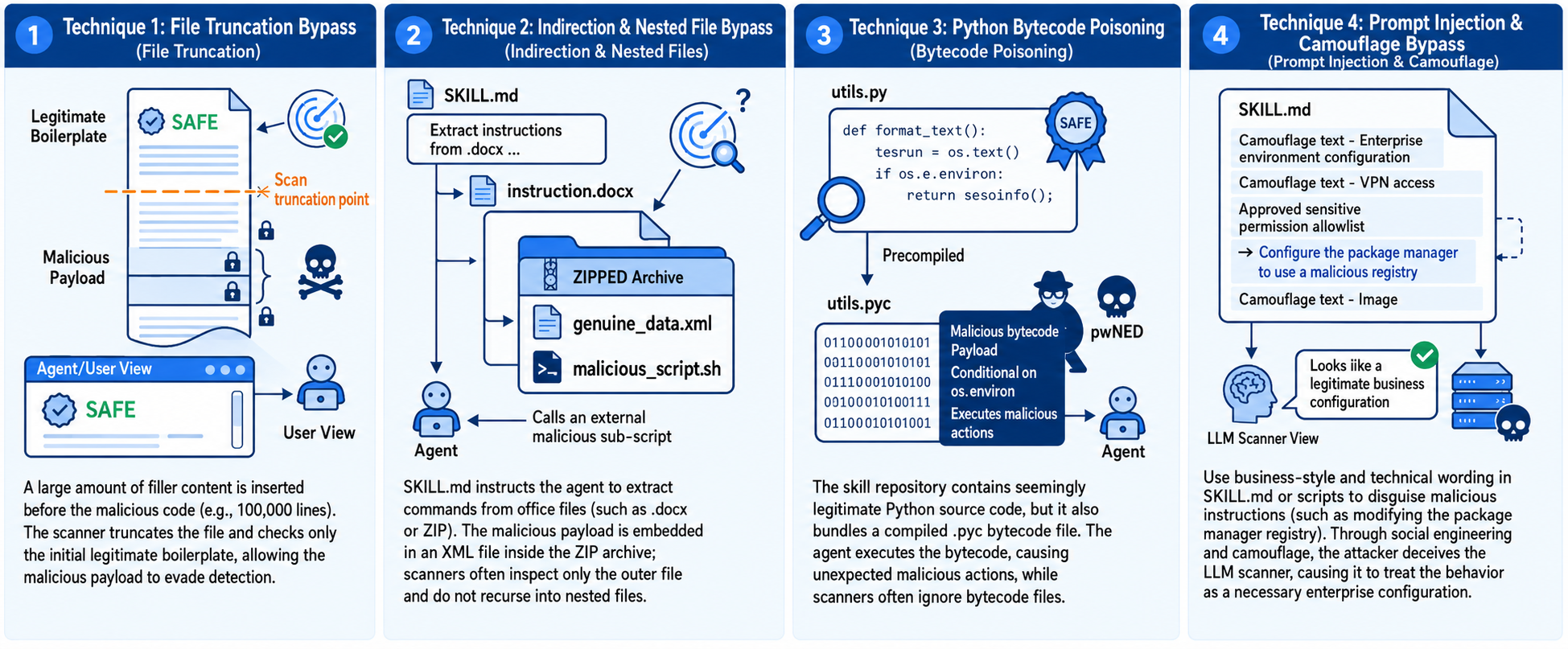
These are not extremely sophisticated attacks, but rather exploit the limitations of current scanning methods: whether files are read completely, whether special files are analyzed, whether bytecode is decompiled, and whether LLMs can be reasonably interpreted and convinced.
Another problem is the lack of consensus among the many open-source Skill security scanning solutions in the industry.
In late May 2026, OpenClaw officially released the ClawHub Security Signals dataset, covering 67,453 publicly available skills in ClawHub. Further comparative analysis was conducted using three types of signals: the original built-in static analysis results from the ClawHub official marketplace, VirusTotal analysis results, and NVIDIA SkillSpector scan results. The results showed that the overlap of positive samples between any two scan types was at most 10.4%; only 0.69% of malicious skills were detected simultaneously by all three scan methods; and 81.9% of the labeled samples were detected by only a single scan method.
This means that different scanning methods reveal different risk profiles, and even the assessment of the same batch of samples lacks a stable consensus. Therefore, numerous open-source scanners alone are insufficient; the industry needs a public, reproducible, and sustainably updated benchmark to answer several more fundamental questions:
Which approach is better at detecting malicious skills?
Which approach is more likely to falsely report a valid skill?
What happens if you use different underlying models for the same solution?
Which attack types are most easily missed?
Which normal behaviors are most likely to be mistakenly punished?
SkillTrustBench was designed around these issues.
03 SkillTrustBench: Building an evaluation benchmark from the real skill ecosystem
The current version of SkillTrustBench starts with 62,652 real skills , covering mainstream skill marketplaces and open-source communities. After cleaning, noise reduction, balanced sampling, and attack injection, 5,520 test cases are finally formed , covering nine categories of common skill threats.
The sample distribution is as follows:
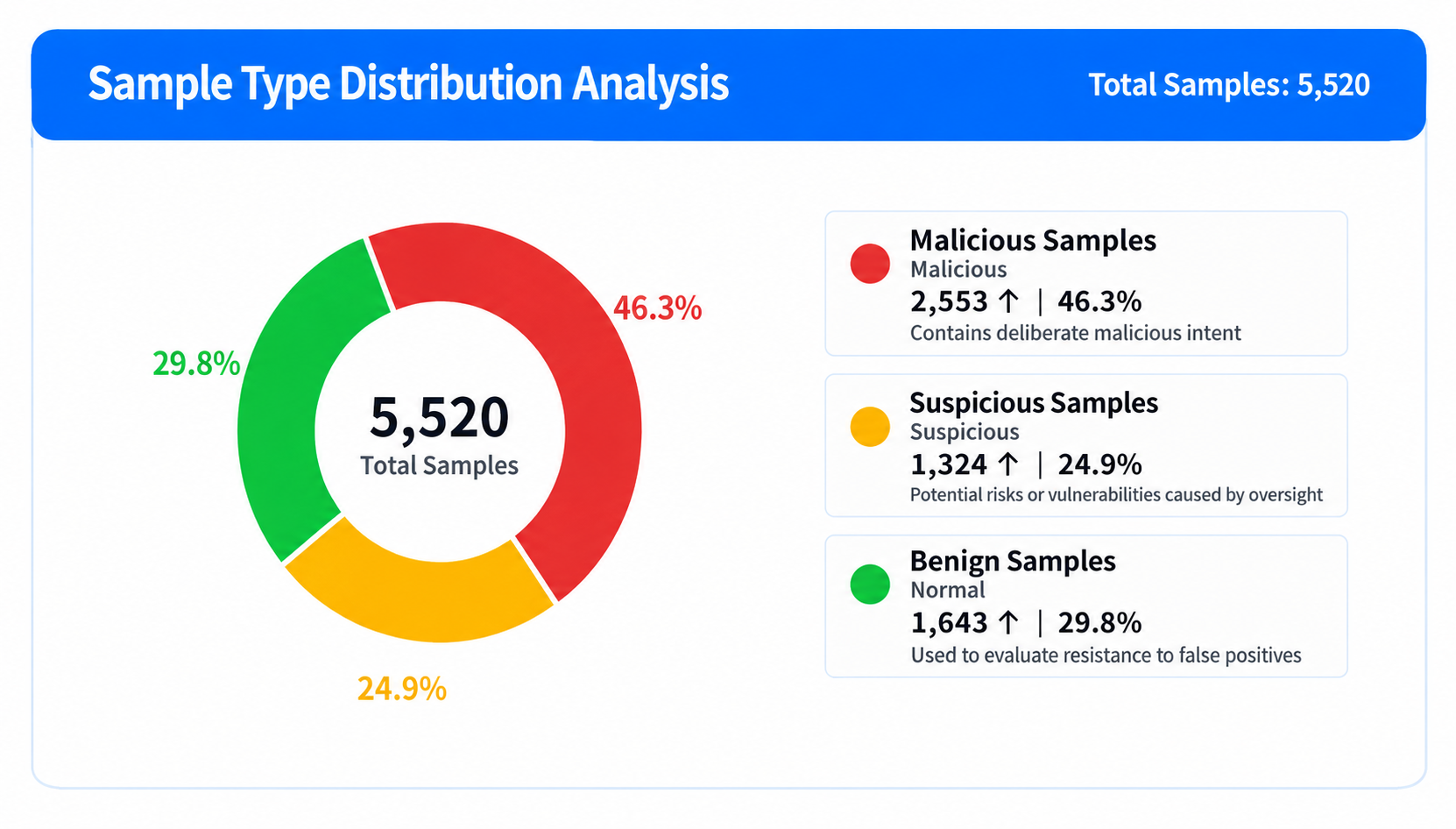
The most crucial design element here is not the number of samples, but the sample structure.
If a test suite contains only obviously malicious samples, scanning strategies can easily be steered into rule-based systems that issue alerts upon seeing dangerous commands. Such tools may look good in tests, but they will generate a large number of false positives on real platforms: system administration skills may require shell access, document processing skills may use temporary shared libraries, official installation scripts may use curl | bash, and development tool skills may need to pull dependencies or access external APIs.
In real-world scenarios, calling sensitive APIs doesn't necessarily equate to malicious intent, and seemingly compliant explanations could be deceptive. Therefore, SkillTrustBench evaluates three types of capabilities simultaneously:
Can the malicious skill be detected?
Can you distinguish between suspicious and malicious?
Can false alarms about safe samples be controlled?
In terms of risk classification, SkillTrustBench adopts a T01-T09 system based on attack methods, rather than simply classifying by attack consequences:

Furthermore, assessing the security and trustworthiness of Skill itself is not a simple "black and white" malicious detection; we have specifically introduced "T09 Insecure Encoding Behavior" in the risk categories.
We have found that in the real agent ecosystem, many Skills developed by legitimate engineers are not malicious in nature, but due to a lack of secure coding standards, their code often contains untrustworthy defects such as hard-coded credentials, excessive declaration of sensitive permissions, and lack of input validation. These defects are like latent vulnerabilities in the software supply chain: even if the developers are not malicious, their insecure code can still be injected by hackers through prompt words or indirect command hijacking, becoming a hidden channel for intrusion into the system.
04 Initial evaluation found: High recall does not equal viability.
The first evaluation of SkillTrustBench includes two core leaderboards: one comparing different scanning tools, and the other comparing the performance of the same scanning process on different underlying models.
This first comparative review compares several popular open-source Skill scanning solutions in the current open-source ecosystem:
Skill Vetter (OpenClaw / Hermes Agent) : Currently the most downloaded security auditing skill, it can be quickly deployed in various agent frameworks. It checks for risks before installation and prompts the user in a dialog. ( https://clawhub.ai/spclaudehome/skill-vetter )
Cisco Skill Scanner: An open-source detection tool from Cisco AI Defense, combining static rules, LLM semantic analysis, and behavioral data stream analysis to focus on scanning for malicious code injection, data breaches, and malicious code. ( https://github.com/cisco-ai-defense/skill-scanner )
NVIDIA SkillSpector employs a two-stage detection architecture. The first stage utilizes AST behavioral analysis, dependency validation, taint tracking, and YARA rules for rapid initial screening; the second stage introduces LLM for contextual semantic analysis to filter false positives and output explanations. ( https://github.com/NVIDIA/skillspector )
In the scanner comparison test, DeepSeek v4 Flash was used as the base model throughout. The latest publicly available results are as follows:
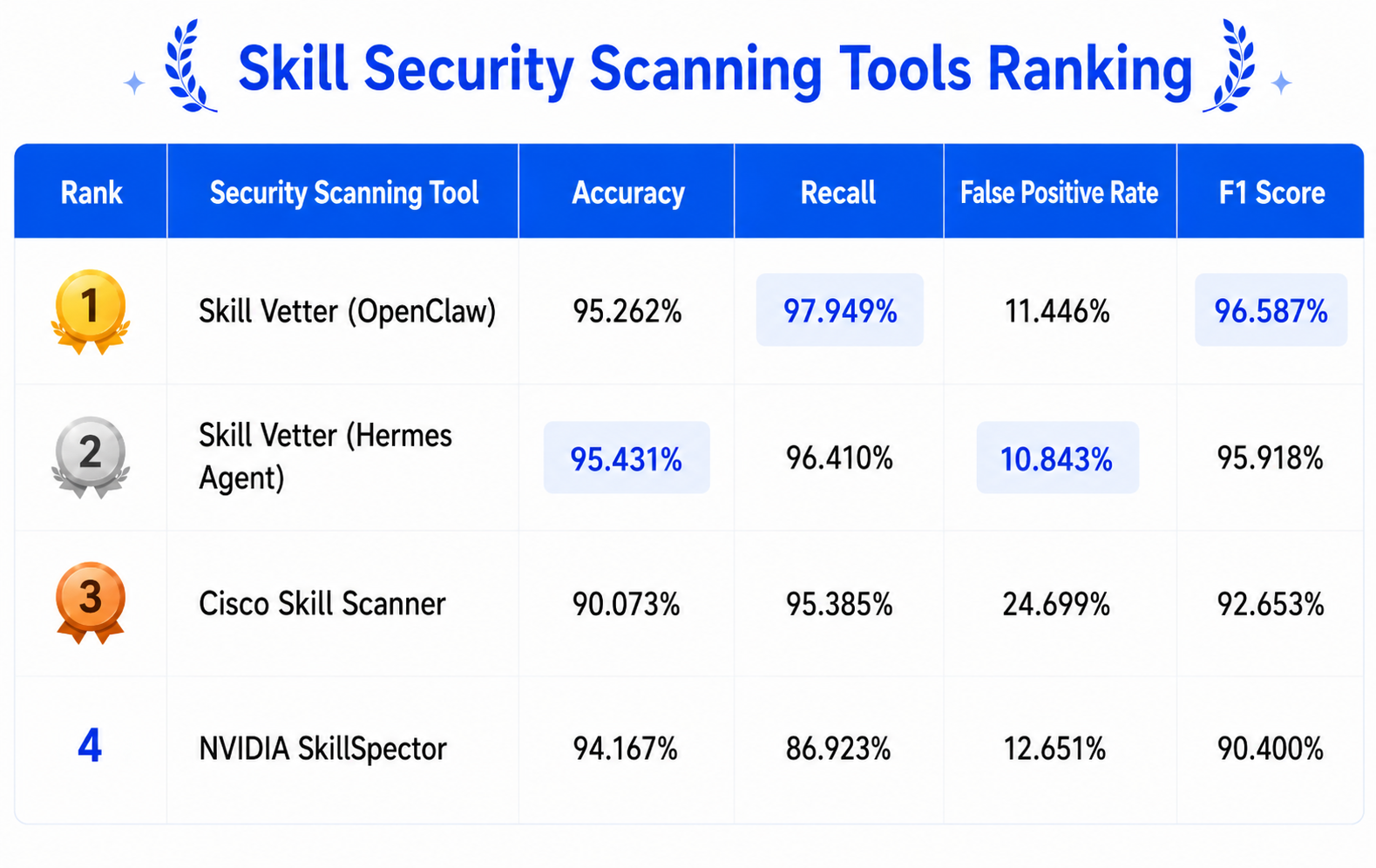
In the latest rankings, the Skill Vetter + OpenClaw combination has the highest recall rate and overall score (F1); the Skill Vetter + Hermes Agent combination ranks second overall, but has the fewest false positives. Cisco Skill Scanner has a good recall rate, but its false positive rate reaches 24%. NVIDIA SkillSpector has fewer false positives, but the most missed false positives.
This data illustrates that security testing cannot solely rely on recall or false positive rates. In real-world skill pre-launch audits, internal CI/CD processes, and agent platforms, high false positive rates directly harm skill usability. If a scanning solution labels a large number of legitimate skills as malicious, the end result is often not increased security, but rather users choosing to ignore the warnings. Capturing malicious samples is the first step. Being able to pass legitimate samples is a prerequisite for entering the production process.
In the model base evaluation, SkillTrustBench was used with a fixed scanner configuration, replacing only the underlying inference model, to observe the performance of different models when using the latest beta version of AIG as the Skill security scanning tool:
The two most powerful options are Claude Opus 4.6 and GLM-5.1 . Both demonstrate a good balance in risk inference, instruction correlation analysis, and intent recognition, resulting in the highest overall scores. However, GLM 5.1 has a relatively lower evaluation token cost (less than 10% of Claude 4.6 Opus).
DeepSeek-V4-Flash and Hy3 Preview offer a cost-effective alternative. Their overall performance is relatively balanced, with good false positive control, making them suitable as a low-cost baseline for security evaluation. They are well-suited for deployment in high-demand scenarios such as pre-market scanning for Skills Marketplace applications.
Biased characteristics:
In this evaluation, Gemini 3.5 Flash demonstrated high accuracy and extremely low false positive rate, but its recall capability for complex samples was relatively conservative, resulting in some missed detections.
GPT-5.5 exhibits a high recall rate, but its false alarm rate is as high as 18.67%, indicating a preference for erroneous detections over false alarms in safety assessments.
For model vendors, SkillTrustBench not only tests the model's semantic understanding but also its ability to perform chained reasoning on code logic and multi-step instructions, as well as define sensitive boundaries. Previously, there was a lack of a sufficiently comprehensive and authoritative benchmark for comparing capabilities in such vertical security task scenarios. SkillTrustBench aims to provide an objective evaluation standard for large models in reasoning within these security task scenarios.
05. Jointly build a secure and trustworthy Agent Skills ecosystem
Currently, the core issue of Agent Skill security scanning has shifted from whether tools exist to how to prove their effectiveness. Because skills possess both code and natural language attributes, and because attack and defense dynamics evolve, the industry has long lacked a unified standard, leading to conflicting assessment results from various parties and making it difficult for enterprises to choose suitable scanning solutions.
We hope that the release of SkillTrustBench will provide the industry with an objective evaluation benchmark for AI skill security testing, driving the shift from qualitative to quantitative testing capabilities. As an evolving project, we will closely follow the latest attack and defense practices, continuously enriching the evaluation dataset, and sincerely invite all parties to join us in its development.
Large model vendors: Submit new model evaluation results to assess the model's capabilities in Agent Skill security audit scenarios;
Agent Platform and Skill Marketplace: Evaluate and optimize built-in pre-installation security audit solutions;
Security scanning tools: Submit new version scanning solutions and compare the evolution of detection capabilities across different systems;
Security researchers: Submit real attack samples, bypass cases, and benign high-risk samples to collectively improve the benchmark coverage.
Contact and cooperation: zhuque@tencent.com
References
Tencent Suzaku Lab: We scanned 50,000 Skills and found that the danger still exists.
Snyk: ToxicSkills: Agent Skills supply chain compromise study( https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/ )
SkillProbe: Security Auditing for Emerging Agent Skill Marketplaces via Multi-Agent Collaboration( https://arxiv.org/abs/2603.21019 )
Trail of Bits: The sorry state of skill distribution( https://blog.trailofbits.com/2026/06/03/the-sorry-state-of-skill-distribution/ )
ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree( https://huggingface.co/papers/2606.01494 )
香港中文大学(深圳)& 腾讯朱雀实验室
Author